sql
Khóa học miễn phí SQL – Non-Clustered Index nhận dự án làm có lương
SQL – Non-Clustered Index

SQL Non-Clustered Indexes
The SQL Non-Clustered index is similar to the Clustered index. When defined on a column, it creates a special table which contains the copy of indexed columns along with a pointer that refers to the location of the actual data in the table. However, unlike Clustered indexes, a Non-Clustered index cannot physically sort the indexed columns.
Following are some of the key points of the Non-clustered index in SQL −
- The non-clustered indexes are a type of index used in databases to speed up the execution time of database queries.
- These indexes require less storage space than clustered indexes because they do not store the actual data rows.
- We can create multiple non-clustered indexes on a single table.
MySQL does not have the concept of Non-Clustered indexes. The PRIMARY KEY (if exists) and the first NOT NULL UNIQUE KEY(if PRIMARY KEY does not exist) are considered clustered indexes in MySQL; all the other indexes are called Secondary Indexes and are implicitly defined.
To get a better understanding, look at the following figure illustrating the working of non-clustered indexes −
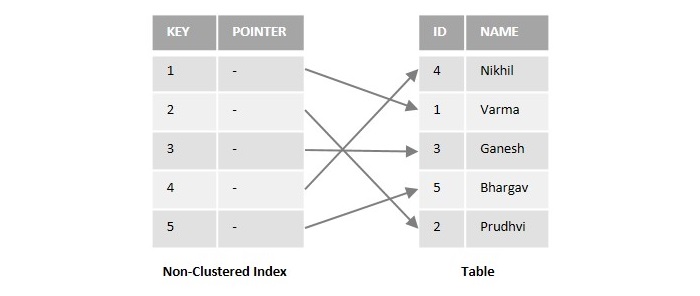
Assume we have a sample database table with two columns named ID and NAME. If we create a non-clustered index on a column named ID in the above table, it will store a copy of the ID column with a pointer that points to the specific location of the actual data in the table.
Syntax
Following is the syntax to create a non-clustered index in SQL Server −
CREATE NONCLUSTERED INDEX index_name ON table_name (column_name)
Here,
- index_name: holds the name of non-clustered index.
- table_name: holds the name of the table where you want to create the non-clustered index.
- column_name: holds the name of the column that you want to define the non-clustered index on.
Example
Let us create a table named CUSTOMERS using the following query −
CREATE TABLE CUSTOMERS( ID INT NOT NULL, NAME VARCHAR (20) NOT NULL, AGE INT NOT NULL, ADDRESS CHAR (25), SALARY DECIMAL (20, 2), );
Let us insert some values into the above-created table using the following query −
INSERT INTO CUSTOMERS VALUES (7, ''Muffy'', ''24'', ''Indore'', 5500), (1, ''Ramesh'', ''32'', ''Ahmedabad'', 2000), (6, ''Komal'', ''22'', ''Hyderabad'', 9000), (2, ''Khilan'', ''25'', ''Delhi'', 1500), (4, ''Chaitali'', ''25'', ''Mumbai'', 6500), (5, ''Hardik'',''27'', ''Bhopal'', 8500), (3, ''Kaushik'', ''23'', ''Kota'', 2000);
The table is successfully created in the SQL database.
| ID | NAME | AGE | ADDRESS | SALARY |
|---|---|---|---|---|
| 7 | Muffy | 24 | Indore | 5500.00 |
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 6 | Komal | 22 | Hyderabad | 9000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 3 | Kaushik | 23 | Kota | 2500.00 |
Now, let us create a non-clustered index on a single column named ID using the following query −
CREATE NONCLUSTERED INDEX NON_CLU_ID ON customers (ID ASC);
Output
On executing the above query, the output is displayed as follows −
Commands Completed Successfully.
Verification
Let us retrieve all the indexes that are created on the CUSTOMERS table using the following query −
EXEC sys.sp_helpindex @objname = N''CUSTOMERS
As we observe, we can find the column named ID in the list of indexes.
| index_name | index_description | index_keys | |
|---|---|---|---|
| 1 | NON_CLU_ID | nonclustered located on PRIMARY | ID |
Now, retrieve the CUSTOMERS table again using the following query to check whether the table is sorted or not −
SELECT * FROM CUSTOMERS;
As we observe, the non-clustered index does not sort the rows physically instead, it creates a separate key-value structure from the table data.
| ID | NAME | AGE | ADDRESS | SALARY |
|---|---|---|---|---|
| 7 | Muffy | 24 | Indore | 5500.00 |
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 6 | Komal | 22 | Hyderabad | 9000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 3 | Kaushik | 23 | Kota | 2500.00 |
Creating Non-Clustered Index on Multiple Columns
Instead of creating a new table, let us consider the previously created CUSTOMERS table. Now, try to create a non-clustered index on multiple columns of the table such as ID, AGE and SALARY using the following query −
CREATE NONCLUSTERED INDEX NON_CLUSTERED_ID ON CUSTOMERS (ID, AGE, SALARY);
Output
The below query will create three separate non-clustered indexes for ID, AGE, and SALARY.
Commands Completed Successfully.
Verification
Let us retrieve all the indexes that are created on the CUSTOMERS table using the following query −
EXEC sys.sp_helpindex @objname = N''CUSTOMERS
As we observe, we can find the column names ID, AGE and SALARY columns in the list of indexes.
| index_name | index_description | index_keys | |
|---|---|---|---|
| 1 | NON_CLU_ID | nonclustered located on PRIMARY | ID, AGE, SALARY |
Khóa học lập trình tại Toidayhoc vừa học vừa làm dự án vừa nhận lương: Khóa học lập trình nhận lương tại trung tâm Toidayhoc
Notice: Trying to access array offset on value of type bool in /home/edua/htdocs/edu.toidayhoc.com/wp-content/themes/flatsome/flatsome/inc/shortcodes/share_follow.php on line 41