Your cart is currently empty!
Category: sqlalchemy
-
Khóa học miễn phí Textual SQL nhận dự án làm có lương
SQLAlchemy ORM – Textual SQL
Earlier, textual SQL using text() function has been explained from the perspective of core expression language of SQLAlchemy. Now we shall discuss it from ORM point of view.
Literal strings can be used flexibly with Query object by specifying their use with the text() construct. Most applicable methods accept it. For example, filter() and order_by().
In the example given below, the filter() method translates the string “id<3” to the WHERE id<3
from sqlalchemy import text for cust in session.query(Customers).filter(text("id<3")): print(cust.name)The raw SQL expression generated shows conversion of filter to WHERE clause with the code illustrated below −
SELECT customers.id AS customers_id, customers.name AS customers_name, customers.address AS customers_address, customers.email AS customers_email FROM customers WHERE id<3
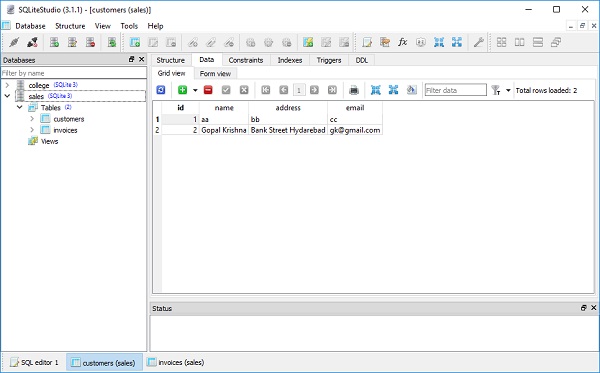
From our sample data in Customers table, two rows will be selected and name column will be printed as follows −
Ravi Kumar Komal Pande
To specify bind parameters with string-based SQL, use a colon,and to specify the values, use the params() method.
cust = session.query(Customers).filter(text("id = :value")).params(value = 1).one()The effective SQL displayed on Python console will be as given below −
SELECT customers.id AS customers_id, customers.name AS customers_name, customers.address AS customers_address, customers.email AS customers_email FROM customers WHERE id = ?
To use an entirely string-based statement, a text() construct representing a complete statement can be passed to from_statement().
session.query(Customers).from_statement(text("SELECT * FROM customers")).all()The result of above code will be a basic SELECT statement as given below −
SELECT * FROM customers
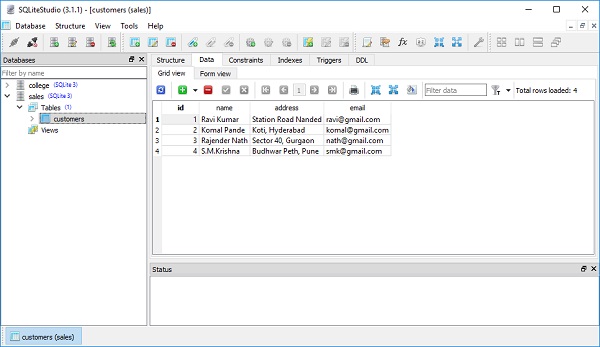
Obviously, all records in customers table will be selected.
The text() construct allows us to link its textual SQL to Core or ORM-mapped column expressions positionally. We can achieve this by passing column expressions as positional arguments to the TextClause.columns() method.
stmt = text("SELECT name, id, name, address, email FROM customers") stmt = stmt.columns(Customers.id, Customers.name) session.query(Customers.id, Customers.name).from_statement(stmt).all()The id and name columns of all rows will be selected even though the SQLite engine executes following expression generated by above code shows all columns in text() method −
SELECT name, id, name, address, email FROM customers
Khóa học lập trình tại Toidayhoc vừa học vừa làm dự án vừa nhận lương: Khóa học lập trình nhận lương tại trung tâm Toidayhoc
Khóa học miễn phí Building Relationship nhận dự án làm có lương
SQLAlchemy ORM – Building Relationship
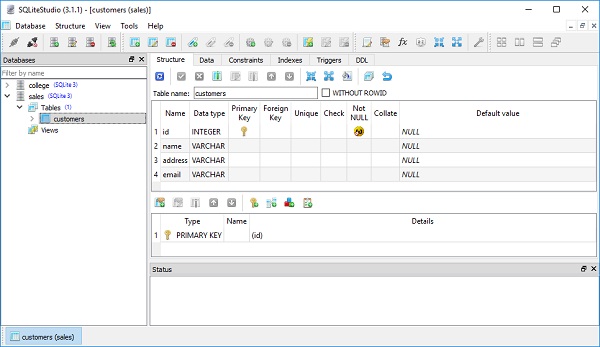
This session describes creation of another table which is related to already existing one in our database. The customers table contains master data of customers. We now need to create invoices table which may have any number of invoices belonging to a customer. This is a case of one to many relationships.
Using declarative, we define this table along with its mapped class, Invoices as given below −
from sqlalchemy import create_engine, ForeignKey, Column, Integer, String
engine = create_engine(''sqlite:///sales.db'', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
from sqlalchemy.orm import relationship
class Customer(Base):
__tablename__ = ''customers''
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
class Invoice(Base):
__tablename__ = ''invoices''
id = Column(Integer, primary_key = True)
custid = Column(Integer, ForeignKey(''customers.id''))
invno = Column(Integer)
amount = Column(Integer)
customer = relationship("Customer", back_populates = "invoices")
Customer.invoices = relationship("Invoice", order_by = Invoice.id, back_populates = "customer")
Base.metadata.create_all(engine)
This will send a CREATE TABLE query to SQLite engine as below −
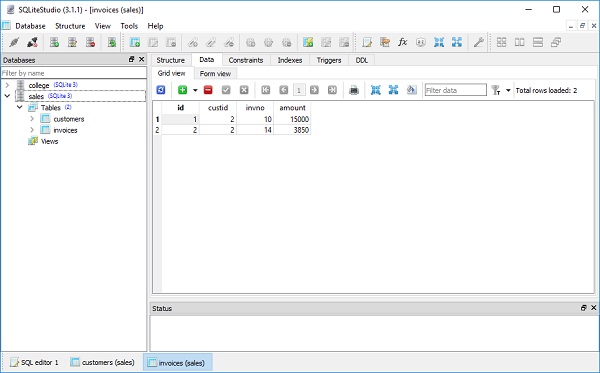
CREATE TABLE invoices ( id INTEGER NOT NULL, custid INTEGER, invno INTEGER, amount INTEGER, PRIMARY KEY (id), FOREIGN KEY(custid) REFERENCES customers (id) )
We can check that new table is created in sales.db with the help of SQLiteStudio tool.
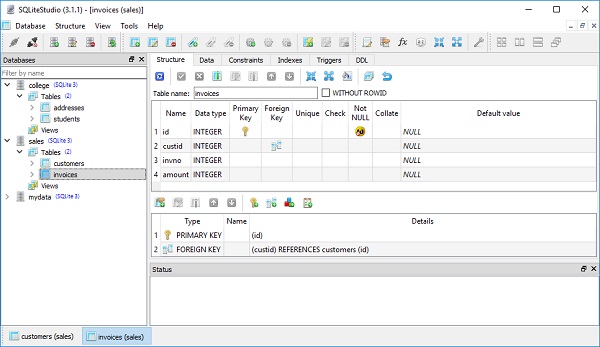
Invoices class applies ForeignKey construct on custid attribute. This directive indicates that values in this column should be constrained to be values present in id column in customers table. This is a core feature of relational databases, and is the “glue” that transforms unconnected collection of tables to have rich overlapping relationships.
A second directive, known as relationship(), tells the ORM that the Invoice class should be linked to the Customer class using the attribute Invoice.customer. The relationship() uses the foreign key relationships between the two tables to determine the nature of this linkage, determining that it is many to one.
An additional relationship() directive is placed on the Customer mapped class under the attribute Customer.invoices. The parameter relationship.back_populates is assigned to refer to the complementary attribute names, so that each relationship() can make intelligent decision about the same relationship as expressed in reverse. On one side, Invoices.customer refers to Invoices instance, and on the other side, Customer.invoices refers to a list of Customers instances.
The relationship function is a part of Relationship API of SQLAlchemy ORM package. It provides a relationship between two mapped classes. This corresponds to a parent-child or associative table relationship.
Following are the basic Relationship Patterns found −
One To Many
A One to Many relationship refers to parent with the help of a foreign key on the child table. relationship() is then specified on the parent, as referencing a collection of items represented by the child. The relationship.back_populates parameter is used to establish a bidirectional relationship in one-to-many, where the “reverse” side is a many to one.
Many To One
On the other hand, Many to One relationship places a foreign key in the parent table to refer to the child. relationship() is declared on the parent, where a new scalar-holding attribute will be created. Here again the relationship.back_populates parameter is used for Bidirectionalbehaviour.
One To One
One To One relationship is essentially a bidirectional relationship in nature. The uselist flag indicates the placement of a scalar attribute instead of a collection on the “many” side of the relationship. To convert one-to-many into one-to-one type of relation, set uselist parameter to false.
Many To Many
Many to Many relationship is established by adding an association table related to two classes by defining attributes with their foreign keys. It is indicated by the secondary argument to relationship(). Usually, the Table uses the MetaData object associated with the declarative base class, so that the ForeignKey directives can locate the remote tables with which to link. The relationship.back_populates parameter for each relationship() establishes a bidirectional relationship. Both sides of the relationship contain a collection.
Khóa học lập trình tại Toidayhoc vừa học vừa làm dự án vừa nhận lương: Khóa học lập trình nhận lương tại trung tâm Toidayhoc