Your cart is currently empty!
Category: sql
-
Khóa học miễn phí SQL – Delete Join nhận dự án làm có lương
SQL – DELETE JOIN

Table of content
Simple deletion operation in SQL can be performed on a single record or multiple records of a table. And to delete records from multiple tables, the most straightforward approach would be to delete records from one table at a time.
However, SQL makes it easier by allowing the deletion operation to be performed on multiple tables simultaneously. This is achieved using Joins.
The SQL DELETE… JOIN Clause
The purpose of Joins in SQL is to combine records of two or more tables based on common columns/fields. Once the tables are joined, performing the deletion operation on the obtained result-set will delete records from all the original tables at a time.
For example, consider a database of an educational institution. It consists of various tables: Departments, StudentDetails, LibraryPasses, LaboratoryPasses etc. When a set of students are graduated, all their details from the organizational tables need to be removed, as they are unwanted. However, removing the details separately from multiple tables can be cumbersome.
To make it simpler, we will first retrieve the combined data of all graduated students from all the tables using Joins; then, this joined data is deleted from all the tables using DELETE statement. This entire process can be done in one single query.
Syntax
Following is the basic syntax of the SQL DELETE… JOIN statement −
DELETE table(s) FROM table1 JOIN table2 ON table1.common_field = table2.common_field;
When we say JOIN here, we can use any type of Join: Regular Join, Natural Join, Inner Join, Outer Join, Left Join, Right Join, Full Join etc.
Example
To demonstrate this deletion operation, we must first create tables and insert values into them. We can create these tables using CREATE TABLE queries as shown below.
Create a table named CUSTOMERS, which contains the personal details of customers including their name, age, address and salary etc. Using the following query −
CREATE TABLE CUSTOMERS ( ID INT NOT NULL, NAME VARCHAR (20) NOT NULL, AGE INT NOT NULL, ADDRESS CHAR (25), SALARY DECIMAL (18, 2), PRIMARY KEY (ID) );
Now, insert values into this table using the INSERT statement as follows −
INSERT INTO CUSTOMERS VALUES (1, ''Ramesh'', 32, ''Ahmedabad'', 2000.00 ), (2, ''Khilan'', 25, ''Delhi'', 1500.00 ), (3, ''Kaushik'', 23, ''Kota'', 2000.00 ), (4, ''Chaitali'', 25, ''Mumbai'', 6500.00 ), (5, ''Hardik'', 27, ''Bhopal'', 8500.00 ), (6, ''Komal'', 22, ''Hyderabad'', 4500.00 ), (7, ''Muffy'', 24, ''Indore'', 10000.00 );
The table will be created as −
ID NAME AGE ADDRESS SALARY 1 Ramesh 32 Ahmedabad 2000.00 2 Khilan 25 Delhi 1500.00 3 Kaushik 23 Kota 2000.00 4 Chaitali 25 Mumbai 6500.00 5 Hardik 27 Bhopal 8500.00 6 Komal 22 Hyderabad 4500.00 7 Muffy 24 Indore 10000.00 Let us create another table ORDERS, containing the details of orders made and the date they are made on.
CREATE TABLE ORDERS ( OID INT NOT NULL, DATE VARCHAR (20) NOT NULL, CUSTOMER_ID INT NOT NULL, AMOUNT DECIMAL (18, 2) );
Using the INSERT statement, insert values into this table as follows −
INSERT INTO ORDERS VALUES (102, ''2009-10-08 00:00:00'', 3, 3000.00), (100, ''2009-10-08 00:00:00'', 3, 1500.00), (101, ''2009-11-20 00:00:00'', 2, 1560.00), (103, ''2008-05-20 00:00:00'', 4, 2060.00);
The table is displayed as follows −
OID DATE CUSTOMER_ID AMOUNT 102 2009-10-08 00:00:00 3 3000.00 100 2009-10-08 00:00:00 3 1500.00 101 2009-11-20 00:00:00 2 1560.00 103 2008-05-20 00:00:00 4 2060.00 Following DELETE… JOIN query removes records from these tables at once −
DELETE a FROM CUSTOMERS AS a INNER JOIN ORDERS AS b ON a.ID = b.CUSTOMER_ID;
Output
The output will be displayed in SQL as follows −
Query OK, 3 rows affected (0.01 sec)
Verification
We can verify whether the changes are reflected in a table by retrieving its contents using the SELECT statement as follows −
SELECT * FROM CUSTOMERS;
The table is displayed as follows −
ID NAME AGE ADDRESS SALARY 1 Ramesh 32 Ahmedabad 2000.00 5 Hardik 27 Bhopal 8500.00 6 Komal 22 Hyderabad 4500.00 7 Muffy 24 Indore 10000.00 Since, we only deleted records from CUSTOMERS table, the changes will not be reflected in the ORDERS table. We can verify it using the following query.
SELECT * FROM ORDERS;
The ORDERS table is displayed as −
OID DATE CUSTOMER_ID AMOUNT 102 2009-10-08 00:00:00 3 3000.00 100 2009-10-08 00:00:00 3 1500.00 101 2009-11-20 00:00:00 2 1560.00 103 2008-05-20 00:00:00 4 2060.00 DELETE… JOIN with WHERE Clause
The ON clause in DELETE… JOIN query is used to apply constraints on the records. In addition to it, we can also use the WHERE clause to make the filtration stricter. Observe the query below. Here, we are deleting the records of customers, in the CUSTOMERS table, whose salary is lower than Rs. 2000.00.
DELETE a FROM CUSTOMERS AS a INNER JOIN ORDERS AS b ON a.ID = b.CUSTOMER_ID WHERE a.SALARY < 2000.00;
Output
On executing the query, following output is displayed.
Query OK, 1 row affected (0.01 sec)
Verification
We can verify whether the changes are reflected in a table by retrieving its contents using the SELECT statement as follows −
SELECT * FROM CUSTOMERS;
The CUSTOMERS table after deletion is as follows −
ID NAME AGE ADDRESS SALARY 1 Ramesh 32 Ahmedabad 2000.00 3 Kaushik 23 Kota 2000.00 4 Chaitali 25 Mumbai 6500.00 5 Hardik 27 Bhopal 8500.00 6 Komal 22 Hyderabad 4500.00 7 Muffy 24 Indore 10000.00 Since we only deleted records from the CUSTOMERS table, the changes will not be reflected in the ORDERS table. We can verify it using the following query −
SELECT * FROM ORDERS;
The ORDERS table is displayed as −
OID DATE CUSTOMER_ID AMOUNT 102 2009-10-08 00:00:00 3 3000.00 100 2009-10-08 00:00:00 3 1500.00 101 2009-11-20 00:00:00 2 1560.00 103 2008-05-20 00:00:00 4 2060.00
Khóa học lập trình tại Toidayhoc vừa học vừa làm dự án vừa nhận lương: Khóa học lập trình nhận lương tại trung tâm Toidayhoc
Khóa học miễn phí SQL – Self Join nhận dự án làm có lương
SQL – Self Join
Self Join, as its name suggests, is a type of join that combines the records of a table with itself.
Suppose an organization, while organizing a Christmas party, is choosing a Secret Santa among its employees based on some colors. It is designed to be done by assigning one color to each of its employees and having them pick a color from the pool of various colors. In the end, they will become the Secret Santa of an employee this color is assigned to.
As we can see in the figure below, the information regarding the colors assigned and a color each employee picked is entered into a table. The table is joined to itself using self join over the color columns to match employees with their Secret Santa.
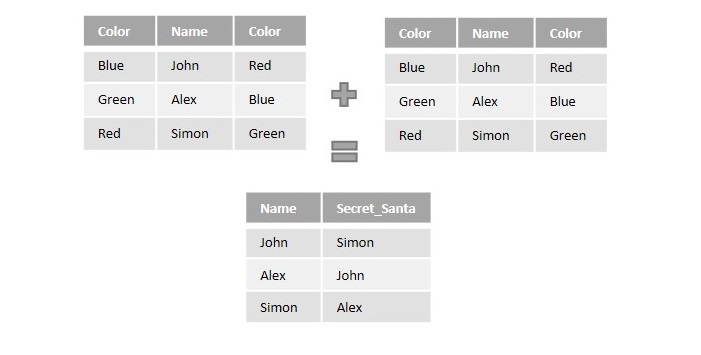
The SQL Self Join
The SQL Self Join is used to join a table to itself as if the table were two tables. To carry this out, alias of the tables should be used at least once.
Self Join is a type of inner join, which is performed in cases where the comparison between two columns of a same table is required; probably to establish a relationship between them. In other words, a table is joined with itself when it contains both Foreign Key and Primary Key in it.
Unlike queries of other joins, we use WHERE clause to specify the condition for the table to combine with itself; instead of the ON clause.
Syntax
Following is the basic syntax of SQL Self Join −
SELECT column_name(s) FROM table1 a, table1 b WHERE a.common_field = b.common_field;
Here, the WHERE clause could be any given expression based on your requirement.
Example
Self Join only requires one table, so, let us create a CUSTOMERS table containing the customer details like their names, age, address and the salary they earn.
CREATE TABLE CUSTOMERS ( ID INT NOT NULL, NAME VARCHAR (20) NOT NULL, AGE INT NOT NULL, ADDRESS CHAR (25), SALARY DECIMAL (18, 2), PRIMARY KEY (ID) );
Now, insert values into this table using the INSERT statement as follows −
INSERT INTO CUSTOMERS VALUES (1, ''Ramesh'', 32, ''Ahmedabad'', 2000.00 ), (2, ''Khilan'', 25, ''Delhi'', 1500.00 ), (3, ''Kaushik'', 23, ''Kota'', 2000.00 ), (4, ''Chaitali'', 25, ''Mumbai'', 6500.00 ), (5, ''Hardik'', 27, ''Bhopal'', 8500.00 ), (6, ''Komal'', 22, ''Hyderabad'', 4500.00 ), (7, ''Muffy'', 24, ''Indore'', 10000.00 );
The table will be created as −
| ID | NAME | AGE | ADDRESS | SALARY |
|---|---|---|---|---|
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | Kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | Hyderabad | 4500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
Now, let us join this table using the following Self Join query. Our aim is to establish a relationship among the said Customers on the basis of their earnings. We are doing this with the help of the WHERE clause.
SELECT a.ID, b.NAME as EARNS_HIGHER, a.NAME as EARNS_LESS, a.SALARY as LOWER_SALARY FROM CUSTOMERS a, CUSTOMERS b WHERE a.SALARY < b.SALARY;
Output
The resultant table displayed will list out all the customers that earn lesser than other customers −
| ID | EARNS_HIGHER | EARNS_LESS | LOWER_SALARY |
|---|---|---|---|
| 2 | Ramesh | Khilan | 1500.00 |
| 2 | Kaushik | Khilan | 1500.00 |
| 6 | Chaitali | Komal | 4500.00 |
| 3 | Chaitali | Kaushik | 2000.00 |
| 2 | Chaitali | Khilan | 1500.00 |
| 1 | Chaitali | Ramesh | 2000.00 |
| 6 | Hardik | Komal | 4500.00 |
| 4 | Hardik | Chaitali | 6500.00 |
| 3 | Hardik | Kaushik | 2000.00 |
| 2 | Hardik | Khilan | 1500.00 |
| 1 | Hardik | Ramesh | 2000.00 |
| 3 | Komal | Kaushik | 2000.00 |
| 2 | Komal | Khilan | 1500.00 |
| 1 | Komal | Ramesh | 2000.00 |
| 6 | Muffy | Komal | 4500.00 |
| 5 | Muffy | Hardik | 8500.00 |
| 4 | Muffy | Chaitali | 6500.00 |
| 3 | Muffy | Kaushik | 2000.00 |
| 2 | Muffy | Khilan | 1500.00 | 1 | Muffy | Ramesh | 2000.00 |
Self Join with ORDER BY Clause
After joining a table with itself using self join, the records in the combined table can also be sorted in an order, using the ORDER BY clause.
Syntax
Following is the syntax for it −
SELECT column_name(s) FROM table1 a, table1 b WHERE a.common_field = b.common_field ORDER BY column_name;
Example
Let us join the CUSTOMERS table with itself using self join on a WHERE clause; then, arrange the records in an ascending order using the ORDER BY clause with respect to a specified column, as shown in the following query.
SELECT a.ID, b.NAME as EARNS_HIGHER, a.NAME as EARNS_LESS, a.SALARY as LOWER_SALARY FROM CUSTOMERS a, CUSTOMERS b WHERE a.SALARY < b.SALARY ORDER BY a.SALARY;
Output
The resultant table is displayed as follows −
| ID | EARNS_HIGHER | EARNS_LESS | LOWER_SALARY |
|---|---|---|---|
| 2 | Ramesh | Khilan | 1500.00 |
| 2 | Kaushik | Khilan | 1500.00 |
| 2 | Chaitali | Khilan | 1500.00 |
| 2 | Hardik | Khilan | 1500.00 |
| 2 | Komal | Khilan | 1500.00 |
| 2 | Muffy | Khilan | 1500.00 |
| 3 | Chaitali | Kaushik | 2000.00 |
| 1 | Chaitali | Ramesh | 2000.00 |
| 3 | Hardik | Kaushik | 2000.00 |
| 1 | Hardik | Ramesh | 2000.00 |
| 3 | Komal | Kaushik | 2000.00 |
| 1 | Komal | Ramesh | 2000.00 |
| 3 | Muffy | Kaushik | 2000.00 |
| 1 | Muffy | Ramesh | 2000.00 |
| 6 | Chaitali | Komal | 4500.00 |
| 6 | Hardik | Komal | 4500.00 |
| 6 | Muffy | Komal | 4500.00 |
| 4 | Hardik | Chaitali | 6500.00 |
| 4 | Muffy | Chaitali | 6500.00 |
| 5 | Muffy | Hardik | 8500.00 |
Not just the salary column, the records can be sorted based on the alphabetical order of names, numerical order of Customer IDs etc.
Khóa học lập trình tại Toidayhoc vừa học vừa làm dự án vừa nhận lương: Khóa học lập trình nhận lương tại trung tâm Toidayhoc