Your cart is currently empty!
Category: sql
-
Khóa học miễn phí SQL – Auto Increment nhận dự án làm có lương
SQL – Auto Increment

Table of content
The SQL Auto Increment is used to automatically add unique sequential values into a column of a table.
We usually define the Auto Increment on a column while creating a table. And when we insert new records into the table, the unique values are added to them.
When we use Auto Increment on a table column, there is no need to insert NOT NULL values to that column. If we provide such values, they will overwrite the unique identities and the increment will be continued (only) on the NULL values (if any); causing ambiguity on the data.
Different RDBMS support the Auto Increment feature in different ways.
Auto Increment in MySQL
In MySQL, you can add the auto-increment feature to a column of a table using the attribute named AUTO_INCREMENT.
By default, when we define the AUTO_INCREMENT attribute on a column, the unique values are generated from “1”; and for each new record we enter into the table, the values in the column will increment by 1. Thus, the first record inserted will have a value of 1, the second record will have a value of 2, and so on.
Syntax
Following is the syntax to add AUTO_INCREMENT attribute to a column of a table in MySQL −
CREATE TABLE table_name( column1 datatype AUTO_INCREMENT, column2 datatype, column3 datatype, ..... columnN datatype );
Example
In the query to we are creating a table named CUSTOMERS and adding the AUTO_INCREMENT to the column named ID −
CREATE TABLE CUSTOMERS( ID INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR (20) NOT NULL, AGE INT NOT NULL, ADDRESS CHAR (25), SALARY DECIMAL (18, 2) );
Now, let us insert values into the CUSTOMERS table using the INSERT statement −
INSERT INTO CUSTOMERS (NAME, AGE, ADDRESS, SALARY) VALUES ("Ramesh", 32, "Ahmedabad", 2000.00), ("Khilan", 25, "Delhi", 1500.00), ("Kaushik", 23, "Kota", 2000.00), ("Chaitali", 25, "Mumbai", 6500.00);Verification
To verify this, you need to retrieve the contents of the CUSTOMERS using the SELECT query as −
SELECT * FROM CUSTOMERS;
Output
Following is the output of the above query, here you can observe that the ID values are generated automatically −
ID NAME AGE ADDRESS SALARY 1 Ramesh 32 Ahmedabad 2000.00 2 Khilan 25 Delhi 1500.00 3 Kaushik 23 Kota 2000.00 4 Chaitali 25 Mumbai 6500.00 AUTO_INCREMENT on Existing Columns
MySQL also allows you to implement the AUTO_INCREMENT attribute on an existing table, using the ALTER TABLE statement.
Following query starts incrementing the ID values from 5 in the CUSTOMERS table CUSTOMERS −
ALTER TABLE CUSTOMERS AUTO_INCREMENT = 100;
Now, let us insert more records to see if the ID values are auto incremented.
INSERT INTO CUSTOMERS(NAME, AGE, ADDRESS, SALARY) VALUES ("Hardik", 27, "Bhopal", 8500.00), ("Komal", 22, "MP", 4500.00), ("Muffy", 24, "Indore", 10000.00);To view the above table data, we use the following SELECT query −
SELECT * FROM CUSTOMERS;
Output
The output of the above query is shown below. It shows the auto increment in action. We are getting the ID values of the newly inserted records begins at 100.
ID NAME AGE ADDRESS SALARY 1 Ramesh 32 Ahmedabad 2000.00 2 Khilan 25 Delhi 1500.00 3 Kaushik 23 Kota 2000.00 4 Chaitali 25 Mumbai 6500.00 100 Hardik 27 Bhopal 8500.00 101 Komal 22 Hyderabad 4500.00 102 Muffy 24 Indore 10000.00 Auto Increment in SQL Server
In SQL Server, there is no direct command/query to perform Auto Increment. Instead, we use the IDENTITY() property. This property works similar to the AUTO_INCREMENT attribute in MySQL. It generates unique, sequential numbers automatically and it is mostly used on the PRIMARY KEY constraint.
Syntax
Following is the basic syntax of IDENTITY() property in SQL Server −
CREATE TABLE table_name ( column1 datatype IDENTITY [(seed, increment)], column2 datatype, column3 datatype, ..... columnN datatype );
This property accepts two parameters. The same are described below:
- seed: It sets the starting value for the auto-incrementing column.
- increment: It specifies how much the value increases by for each new row.
Example
In the following example, we are using the IDENTITY() property on the ID column of table named CUSTOMERS −
CREATE TABLE CUSTOMERS( ID INT PRIMARY KEY IDENTITY(1,1), NAME VARCHAR (20) NOT NULL, AGE INT NOT NULL, ADDRESS CHAR (25), SALARY DECIMAL (18, 2) );
After creating the table, we are inserting some records using the following query −
INSERT INTO CUSTOMERS(NAME, AGE, ADDRESS, SALARY) VALUES (''Ramesh'', 32, ''Ahmedabad'', 2000.00), (''Khilan'', 25, ''Delhi'', 1500.00), (''Kaushik'', 23, ''Kota'', 2000.00), (''Chaitali'', 25, ''Mumbai'', 6500.00);To view the table data, we use the following SELECT query −
SELECT * FROM CUSTOMERS;
Output
Following is an output of the above query, where ID values are generated automatically −
ID NAME AGE ADDRESS SALARY 1 Ramesh 32 Ahmedabad 2000.00 2 Khilan 25 Delhi 1500.00 3 Kaushik 23 Kota 2000.00 4 Chaitali 25 Mumbai 6500.00
Khóa học lập trình tại Toidayhoc vừa học vừa làm dự án vừa nhận lương: Khóa học lập trình nhận lương tại trung tâm Toidayhoc
Khóa học miễn phí SQL – Cursors nhận dự án làm có lương
SQL – Cursors
A database cursor solves the problem of impedance mismatch. It acts as a filter between the result of a SQL query and the statements that process this result.
Cursors in SQL
A Cursor is a temporary memory that is allocated by the database server at the time of performing the Data Manipulation Language operations on a table, such as INSERT, UPDATE and DELETE etc. It is used to retrieve and manipulate data stored in the SQL table.
In MySQL, you cannot declare a cursor directly outside of a stored procedure or function. Cursors are generally declared within stored procedures, functions, or blocks of SQL code in MySQL database.
Using cursors, we can perform multiple operations on each row of a result set, with or without returning the original data.
Properties of Cursors
Following are the properties of MySQL Cursors −
-
READ ONLY − We cannot update or modify any records in the table using the MySQL cursors. We can just fetch and process data from a table.
-
Non-Scrollable − We can retrieve records from a table in a single direction, i.e. from the first record or the last. We cannot move backward or jump to a specific position within the result set.
-
Asensitive Cursor − An asensitive cursor operates directly on the actual data in the database, it does not create a copy of the data. If any change is made to the data by other connections, it can affect the data that the cursor is working with.
In addition to the Asensitive cursor there is another type known as Insensitive Cursor. An insensitive cursor uses a temporary copy of the data. Therefore, these cursors are insensitive (not affected) to the changes that are made in the table.
Life Cycle of the Cursor
There are four steps to manage these cursors. Following diagram illustrates the lifecycle of an SQL cursor −
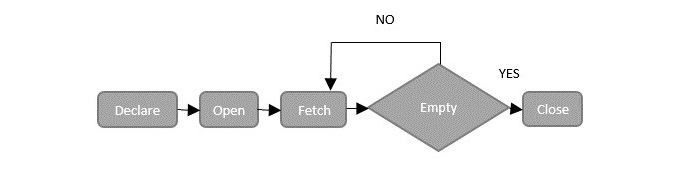
Now, let us discuss the phases of life cycle of the cursor one-by-one.
Declare Cursor Statement
In MySQL we can declare a cursor using the DECLARE statement and associate it with a SELECT statement to retrieve records from a database table.
However, this SELECT statement associated with a cursor does not use the INTO clause, as it”s purpose is to fetch and process rows rather than assigning values to variables.
Syntax
Following is the syntax to declare a cursor in MySQL database −
DECLARE cursor_name CURSOR FOR select_statement;
Open Cursor Statement
After declaring a cursor in MySQL, the next step is to open the cursor using the OPEN statement. It initializes the result-set, allowing us to fetch and process rows from the associated SELECT statement in the cursor.
Syntax
Following is the syntax to open a cursor in MySQL database −
OPEN cursor_name;
Fetch Cursor Statement
Then, we can use the FETCH statement to retrieve the current row pointed by the cursor, and with each FETCH, the cursor moves to the next row in the result set. This allows us to process each row one by one.
Syntax
Following is the syntax to fetch a cursor in MySQL database −
FETCH cursor_name INTO variable_list;
Close Cursor Statement
Once all the rows are fetched, we must close the cursor to release the memory associated with it. We can do this using the CLOSE statement.
Syntax
Following is the syntax to close a cursor in MySQL database −
CLOSE cursor_name;
Example
In this example, let us see how to manage a cursor in a stored procedure.
Assume we have created a table with the name CUSTOMERS using the CREATE TABLE statement as follows −
CREATE TABLE CUSTOMERS ( ID INT NOT NULL, NAME VARCHAR (20) NOT NULL, AGE INT NOT NULL, ADDRESS CHAR (25), SALARY DECIMAL (18, 2), PRIMARY KEY (ID) );
Now, let us insert some records into the CUSTOMERS table using the INSERT statement as follows −
INSERT INTO CUSTOMERS VALUES (1, ''Ramesh'', 32, ''Ahmedabad'', 2000.00 ), (2, ''Khilan'', 25, ''Delhi'', 1500.00 ), (3, ''Kaushik'', 23, ''Kota'', 2000.00 ), (4, ''Chaitali'', 25, ''Mumbai'', 6500.00 );
Now, we will create a backup table named ”CUSTOMERS_BACKUP” to store customer data −
CREATE TABLE CUSTOMERS_BACKUP ( ID INT NOT NULL, NAME VARCHAR (20) NOT NULL, PRIMARY KEY (ID) );
Here, we are creating a stored procedure named FetchCustomers to fetch customer names from the CUSTOMERS table and inserting them one by one into the BACKUP table. We are using a cursor to iterate through the rows and a handler to detect the end of the result-set, ensuring all names are processed −
DELIMITER //
CREATE PROCEDURE FetchCustomers()
BEGIN
DECLARE done INT DEFAULT FALSE;
DECLARE customer_id INT;
DECLARE customer_name VARCHAR(255);
DECLARE auto_id INT;
-- Declare cursor
DECLARE MY_CURSOR CURSOR FOR
SELECT id, name FROM CUSTOMERS;
-- Declare exit handler
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = TRUE;
-- Open cursor
OPEN MY_CURSOR;
-- Fetch and insert rows
read_loop: LOOP
FETCH MY_CURSOR INTO customer_id, customer_name;
IF done = 1 THEN
LEAVE read_loop;
END IF;
-- Insert the fetched data into the backup table
INSERT INTO customers_backup VALUES (customer_id, customer_name);
-- Get the last auto-generated ID used in the insertion
SET auto_id = LAST_INSERT_ID();
END LOOP;
-- Close cursor
CLOSE MY_CURSOR;
END //
DELIMITER ;
Once we create the procedure successfully, we can execute it using the CALL statement as shown below −
CALL FetchCustomers();
Verification
You can verify the contents of the CUSTOMERS_BACKUP table using the SELECT statement as shown below −
SELECT * FROM CUSTOMERS_BACKUP;
The contents of the table would be −
| ID | NAME |
|---|---|
| 1 | Ramesh |
| 2 | Khilan |
| 3 | Kaushik |
| 4 | Chaitali |
Khóa học lập trình tại Toidayhoc vừa học vừa làm dự án vừa nhận lương: Khóa học lập trình nhận lương tại trung tâm Toidayhoc