Your cart is currently empty!
Author: alien
-
Khóa học miễn phí MySQL – Horizontal Partitioning nhận dự án làm có lương
MySQL – Horizontal Partitioning

Table of content
The MySQL Partitioning is a technique that can be used to divide a database table into smaller tables i.e. partitions. These smaller tables are stored in different physical locations and are treated as separate tables. Thus, the data in these smaller tables can be accessed and managed individually.
But note that, even if the data smaller tables is managed separately, they are not independent tables; i.e., they are still a part of main table.
There are two forms of partitioning in MySQL: Horizontal Partitioning and Vertical Partitioning.
MySQL Horizontal Partitioning
The MySQL Horizontal partitioning is used to divide the table rows into multiple partitions. Since it divides the rows, all the columns will be present in each partition. All the partitions can be accessed individually or collectively.
There are several types of MySQL horizontal partitioning methods −
MySQL Range Partitioning
The MySQL RANGE partitioning is used to divide a table into partitions based on a specific range of column values. Each table partition contains rows with column values falling within that defined range.
Example
Let us create a table named CUSTOMERS and partition it by the AGE column into four partitions: P1, P2, P3, and P4 using the “PARTITION BY RANGE” clause −
CREATE TABLE CUSTOMERS( ID int not null, NAME varchar(40) not null, AGE int not null, ADDRESS char(25) not null, SALARY decimal(18, 2) ) PARTITION BY RANGE (AGE) ( PARTITION P1 VALUES LESS THAN (20), PARTITION P2 VALUES LESS THAN (30), PARTITION P3 VALUES LESS THAN (40), PARTITION P4 VALUES LESS THAN (50) );
Here, we are inserting rows into the above created table −
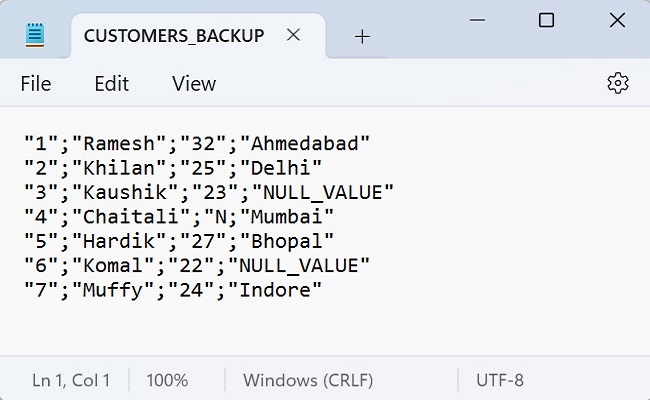
INSERT INTO CUSTOMERS VALUES (1, ''Ramesh'', 19, ''Ahmedabad'', 2000.00 ), (2, ''Khilan'', 25, ''Delhi'', 1500.00 ), (3, ''kaushik'', 23, ''Kota'', 2000.00 ), (4, ''Chaitali'', 31, ''Mumbai'', 6500.00 ), (5, ''Hardik'', 35, ''Bhopal'', 8500.00 ), (6, ''Komal'', 47, ''MP'', 4500.00 ), (7, ''Muffy'', 43, ''Indore'', 10000.00 );
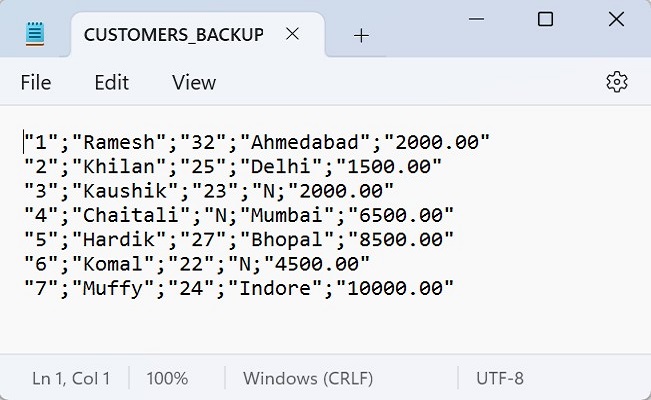
Following is the CUSTOMERS table obtained −
ID NAME AGE ADDRESS SALARY 1 Ramesh 19 Ahmedabad 2000.00 2 Khilan 25 Delhi 1500.00 3 Kaushik 23 Kota 2000.00 4 Chaitali 31 Mumbai 6500.00 5 Hardik 35 Bhopal 8500.00 6 Komal 47 MP 4500.00 7 Muffy 43 Indore 10000.00 Now that we have some data in the CUSTOMERS table, we can display the partition status to see how the data is distributed among the partitions using the following query −
SELECT PARTITION_NAME, TABLE_ROWS FROM INFORMATION_SCHEMA.PARTITIONS WHERE TABLE_NAME=''CUSTOMERS
The above query will show us the number of rows in each partition. For example, P1 has 1 row, P2 has 2 rows, P3 has 2 rows, and P4 has 2 rows as shown below −
PARTITION_NAME TABLE_ROWS P1 1 P2 2 P3 2 P4 2 Displaying Partitions −
We can also display data from specific partitions using the PARTITION clause. For instance, to retrieve data from partition P1, we use the following query −
SELECT * FROM CUSTOMERS PARTITION (p1);
It will display all the records in partition P1 −
ID NAME AGE ADDRESS SALARY 1 Ramesh 19 Ahmedabad 2000.00 Similarly, we can display other partitions using the same syntax.
Handling Data Outside the Range −
If we attempt to insert a value into the AGE column that doesn”t fall within any of the defined partitions, it will fail with an error, as shown below −
INSERT INTO CUSTOMERS VALUES (8, ''Brahmi'', 70, ''Hyderabad'', 19000.00 );
Following is the error obtained −
ERROR 1526 (HY000): Table has no partition for value 70
Truncating Partitions −
We can also manage partitions by truncating them if needed. For example, to empty partition P2, we can use the following query −
ALTER TABLE CUSTOMERS TRUNCATE PARTITION p2;
The output obtained is as shown below −
Query OK, 0 rows affected (0.03 sec)
This will remove all data from partition P2, making it empty as shown below −
SELECT * FROM CUSTOMERS PARTITION (p2);
Following is the output produced −
Empty set (0.00 sec)
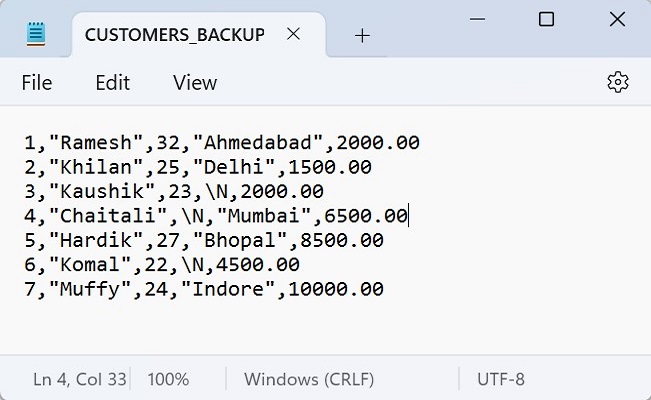
We can verify the CUSTOMERS table using the following SELECT query −
SELECT * FROM CUSTOMERS;
We can see in the table below that the rows belonging to p2 partition are deleted −
ID NAME AGE ADDRESS SALARY 1 Ramesh 19 Ahmedabad 2000.00 2 Khilan 25 Delhi 1500.00 3 Kaushik 23 Kota 2000.00 6 Komal 47 MP 4500.00 7 Muffy 43 Indore 10000.00 MySQL List Partitioning
The MySQL List Partitioning is used to divide the table into partitions based on a discrete set of values for a specific column. Each partition contains rows that match a particular value within the defined set.
Example
In this example, we will create a table named STUDENTS and divide it into four partitions (P1, P2, P3, and P4) based on the “DEPARTMENT_ID” column using the “PARTITION BY LIST” clause −
CREATE TABLE STUDENTS( ID int, NAME varchar(50), DEPARTMENT varchar(50), DEPARTMENT_ID int ) PARTITION BY LIST(DEPARTMENT_ID)( PARTITION P1 VALUES IN (3, 5, 6, 7, 9), PARTITION P2 VALUES IN (13, 15, 16, 17, 20), PARTITION P3 VALUES IN (23, 25, 26, 27, 30), PARTITION P4 VALUES IN (33, 35, 36, 37, 40) );
Here, we are inserting rows into the above-created table −
INSERT INTO STUDENTS VALUES (1, ''Ramesh'', "cse", 5), (2, ''Khilan'', "mech", 20), (3, ''kaushik'', "ece", 17), (4, ''Chaitali'', "eee", 33), (5, ''Hardik'', "IT", 36), (6, ''Komal'', "Hotel management", 40), (7, ''Muffy'', "Fashion", 23);
Following is the STUDENTS table obtained −
ID NAME DEPARTMENT DEPARTMENT_ID 1 Ramesh cse 5 2 Khilan mech 20 3 Kaushik ece 17 7 Muffy Fashion 23 4 Chaitali eee 33 5 Hardik IT 36 6 Komal Hotel management 40 We can display the partition status of the STUDENTS table to see how the data is distributed among partitions using the following query −
SELECT PARTITION_NAME, TABLE_ROWS FROM INFORMATION_SCHEMA.PARTITIONS WHERE TABLE_NAME=''STUDENTS
The output of this query will show the number of rows in each partition. For instance, P1 has 1 row, P2 has 2 rows, P3 has 1 row, and P4 has 3 rows −
PARTITION_NAME TABLE_ROWS P1 1 P2 2 P3 1 P4 3 MySQL Hash Partitioning
The MySQL HASH partitioning is used to divide the table data into partitions using a hash function based on a specific column(s). The data will be evenly distributed among the partitions.
Example
In the following query, we are creating a table with the name EMPLOYEES with four partitions based on the “id” column using the PARTITION BY HASH clause −
CREATE TABLE EMPLOYEES ( id INT NOT NULL, name VARCHAR(50) NOT NULL, department VARCHAR(50) NOT NULL, salary INT NOT NULL ) PARTITION BY HASH(id) PARTITIONS 4;
Here, we are inserting rows into the above-created table −
INSERT INTO EMPLOYEES VALUES (1, ''Varun'', ''Sales'', 50000), (2, ''Aarohi'', ''Marketing'', 60000), (3, ''Paul'', ''IT'', 70000), (4, ''Vaidhya'', ''Finance'', 80000), (5, ''Nikhil'', ''Sales'', 55000), (6, ''Sarah'', ''Marketing'', 65000), (7, ''Tim'', ''IT'', 75000), (8, ''Priya'', ''Finance'', 85000);
The EMPLOYEES table obtained is as follows −
id name department salary 4 Vaidhya Finance 80000 8 Priya Finance 85000 1 Varun Sales 50000 5 Nikhil Sales 55000 2 Aarohi Marketing 60000 6 Sarah Marketing 65000 3 Paul IT 70000 7 Tim IT 75000 The records are evenly distributed among four partitions based on the “id” column. You can verify the partition status using the following SELECT query −
SELECT PARTITION_NAME, TABLE_ROWS FROM INFORMATION_SCHEMA.PARTITIONS WHERE TABLE_NAME=''EMPLOYEES
The table obtained is as follows −
PARTITION_NAME TABLE_ROWS P0 2 P1 2 P2 2 P3 2 Key Partitioning
The MySQL key partitioning is used to divide the table data into partitions based on the values of the primary key or a unique key.
Example
In the following query, we are creating a table with the name PERSON with Key partitioning on the “id” column. We have divided the table into four partitions, and the primary key is “id” −
CREATE TABLE PERSON ( id INT NOT NULL, name VARCHAR(50) NOT NULL, email VARCHAR(50) NOT NULL, address VARCHAR(100) NOT NULL, PRIMARY KEY (id) ) PARTITION BY KEY(id) PARTITIONS 4;
Here, we are inserting rows into the above-created table −
INSERT INTO PERSON VALUES (1, ''Krishna'', ''Krishna@tutorialspoint.com'', ''Ayodhya''), (2, ''Kasyap'', ''Kasyap@tutorialspoint.com'', ''Ayodhya''), (3, ''Radha'', ''Radha@tutorialspoint.com'', ''Ayodhya''), (4, ''Sarah'', ''Sarah@tutorialspoint.com'', ''Sri Lanka''), (5, ''Sita'', ''Sita@tutorialspoint.com'', ''Sri Lanka''), (6, ''Arjun'', ''Arjun@tutorialspoint.com'', ''India''), (7, ''Hanuman'', ''Hanuman@tutorialspoint.com'', ''Sri Lanka''), (8, ''Lakshman'', ''Lakshman@tutorialspoint.com'', ''Sri Lanka'');
Following is the PERSON table obtained −
id name email address 1 Krishna Krishna@tutorialspoint.com Ayodhya 5 Sita Sita@tutorialspoint.com Sri Lanka 4 Sarah Sarah@tutorialspoint.com Sri Lanka 8 Lakshman Lakshman@tutorialspoint.com Sri Lanka 3 Radha Radha@tutorialspoint.com Ayodhya 7 Hanuman Hanuman@tutorialspoint.com Sri Lanka 2 Kasyap Kasyap@tutorialspoint.com Ayodhya 6 Arjun Arjun@tutorialspoint.com India Again, the data is evenly distributed among partitions based on the “id” column, and you can verify the partition status using the query given below −
SELECT PARTITION_NAME, TABLE_ROWS FROM INFORMATION_SCHEMA.PARTITIONS WHERE TABLE_NAME=''PERSON
The output obtained is as shown below −
PARTITION_NAME TABLE_ROWS P0 2 P1 2 P2 2 P3 2 MySQL Sub-partitioning
The MySQL subpartitioning is used to further divide partitions based on another column, often used in conjunction with other partitioning methods like RANGE or HASH.
Example
Let us create a CUSTOMER_ORDERS table with RANGE partitioning on the “order_date” column, and then we will subpartition by hashing on the month of “order_date” −
CREATE TABLE CUSTOMER_ORDERS ( order_id INT NOT NULL, customer_name VARCHAR(50) NOT NULL, order_date DATE NOT NULL, order_status VARCHAR(20) NOT NULL ) PARTITION BY RANGE (YEAR(order_date)) SUBPARTITION BY HASH(MONTH(order_date)) SUBPARTITIONS 2( PARTITION p0 VALUES LESS THAN (2022), PARTITION p1 VALUES LESS THAN (2023), PARTITION p2 VALUES LESS THAN (2024) );
Here, we are inserting rows into the above-created table −
INSERT INTO CUSTOMER_ORDERS VALUES (1, ''John'', ''2021-03-15'', ''Shipped''), (2, ''Bob'', ''2019-01-10'', ''Delivered''), (3, ''Johnson'', ''2023-01-10'', ''Delivered''), (4, ''Jake'', ''2020-01-10'', ''Delivered''), (5, ''Smith'', ''2022-05-01'', ''Pending''), (6, ''Rob'', ''2023-01-10'', ''Delivered'');
Following is the CUSTOMERS_ORDERS table obtained −
order_id customer_name order_date order_status 1 John 2021-03-15 Shipped 2 Bob 2019-01-10 Delivered 4 Jake 2020-01-10 Delivered 5 Smith 2022-05-01 Pending 3 Johnson 2023-01-10 Delivered 6 Rob 2023-01-10 Delivered You can display the CUSTOMER_ORDERS table and verify the partition status using the following query −
SELECT PARTITION_NAME, TABLE_ROWS FROM INFORMATION_SCHEMA.PARTITIONS WHERE TABLE_NAME=''CUSTOMER_ORDERS
Following is the table obtained −
PARTITION_NAME TABLE_ROWS P0 0 P0 3 P1 0 P1 1 P2 0 P2 2
Khóa học lập trình tại Toidayhoc vừa học vừa làm dự án vừa nhận lương: Khóa học lập trình nhận lương tại trung tâm Toidayhoc
Khóa học miễn phí MySQL – Upsert nhận dự án làm có lương
MySQL – Upsert
The MySQL UPSERT Operation
The MySQL UPSERT operation combines INSERT and UPDATE into a single statement, allowing you to insert a new row into a table or update an existing row if it already exists. We can understand in the name (UPSERT) itself, where UP stands for UPDATE and SERT stands for INSERT.
This tutorial covers three common methods to perform UPSERT operations in MySQL: INSERT IGNORE, REPLACE, and INSERT with ON DUPLICATE KEY UPDATE.
UPSERT Using INSERT IGNORE
The INSERT IGNORE statement in MySQL allows you to insert a new record into a table. If a record with the same primary key already exists, it ignores the error and doesn”t insert the new record.
Example
First, let us create a table with the name COURSES using the following query −
CREATE TABLE COURSES( ID int, COURSE varchar(50) primary key, COST int );
Here, we are inserting records into the COURSES table −
INSERT INTO COURSES VALUES (1, "HTML", 3000), (2, "CSS", 4000), (3, "JavaScript", 6000), (4, "Node.js", 10000), (5, "React.js", 12000), (6, "Angular", 8000), (7, "Php", 9000);
The COURSES table obtained is as follows −
| ID | COURSE | COST |
|---|---|---|
| 6 | Angular | 8000 |
| 2 | CSS | 4000 |
| 1 | HTML | 3000 |
| 3 | JavaScript | 6000 |
| 4 | Node.js | 10000 |
| 7 | Php | 9000 |
| 5 | React.js | 12000 |
Now, we attempt to insert a duplicate record using the INSERT INTO statement in the following query −
INSERT INTO COURSES VALUES (6, ''Angular'', 9000);
This results in an error because a duplicate record cannot be inserted −
ERROR 1062 (23000): Duplicate entry ''Angular'' for key ''courses.PRIMARY''
Using INSERT IGNORE −
Now, let us perform the same operation using INSERT IGNORE statement −
INSERT IGNORE INTO COURSES VALUES (6, ''Angular'', 9000);
Output
As we can see in the output below, the INSERT IGNORE statement ignores the error −
Query OK, 0 rows affected, 1 warning (0.00 sec)
Verification
We can verify the COURSES table to see that the error was ignored using the following SELECT query −
SELECT * FROM COURSES;
The table obtained is as follows −
| ID | COURSE | COST |
|---|---|---|
| 6 | Angular | 8000 |
| 2 | CSS | 4000 |
| 1 | HTML | 3000 |
| 3 | JavaScript | 6000 |
| 4 | Node.js | 10000 |
| 7 | Php | 9000 |
| 5 | React.js | 12000 |
UPSERT Using REPLACE
The MySQL REPLACE statement first attempts to delete the existing row if it exists and then inserts the new row with the same primary key. If the row does not exist, it simply inserts the new row.
Example
Let us replace or update a row in the COURSES table. If a row with COURSE “Angular” already exists, it will update its values for ID and COST with the new values provided. Else, a new row will be inserted with the specified values in the query −
REPLACE INTO COURSES VALUES (6, ''Angular'', 9000);
Output
The output for the query above produced is as given below −
Query OK, 2 rows affected (0.01 sec)
Verification
Now, let us verify the COURSES table using the following SELECT query −
SELECT * FROM COURSES;
We can see in the following table, the REPLACE statement added a new row after deleting the duplicate row −
| ID | COURSE | COST |
|---|---|---|
| 6 | Angular | 9000 |
| 2 | CSS | 4000 |
| 1 | HTML | 3000 |
| 3 | JavaScript | 6000 |
| 4 | Node.js | 10000 |
| 7 | Php | 9000 |
| 5 | React.js | 12000 |
UPSERT Using INSERT with ON DUPLICATE KEY UPDATE
The INSERT … ON DUPLICATE KEY UPDATE statement in MySQL attempts to insert a new row. If the row already exists, it updates the existing row with the new values specified in the statement.
Example
Here, we are updating the duplicate record using the following query −
INSERT INTO COURSES VALUES (6, ''Angular'', 9000) ON DUPLICATE KEY UPDATE ID = 6, COURSE = ''Angular'', COST = 20000;
Output
As we can see in the output below, no error is generated and the duplicate row gets updated.
Query OK, 2 rows affected (0.01 sec)
Verification
Let us verify the COURSES table using the following SELECT query −
SELECT * FROM COURSES;
As we can see the table below, the INSERT INTO… ON DUPLICATE KEY UPDATE statement updated the duplicate record −
| ID | COURSE | COST |
|---|---|---|
| 6 | Angular | 20000 |
| 2 | CSS | 4000 |
| 1 | HTML | 3000 |
| 3 | JavaScript | 6000 |
| 4 | Node.js | 10000 |
| 7 | Php | 9000 |
| 5 | React.js | 12000 |
Khóa học lập trình tại Toidayhoc vừa học vừa làm dự án vừa nhận lương: Khóa học lập trình nhận lương tại trung tâm Toidayhoc