Your cart is currently empty!
Author: alien
-
Khóa học miễn phí SQL – Drop Index nhận dự án làm có lương
SQL – Drop Index

Table of content
The DROP statement in SQL is used to remove or delete an existing database object such as a table, index, view, or procedure. Whenever we use DROP statement with any of the database objects, it will remove them permanently along with their associated data.
And when that database object is an index, the DROP INDEX statement in SQL is used.
Dropping an SQL Index
An SQL Index can be dropped from a database table using the DROP INDEX statement.
It is important to understand that dropping an index can have a significant impact on the performance of your database queries. Therefore, only try to remove an index if you are sure that it is no longer required.
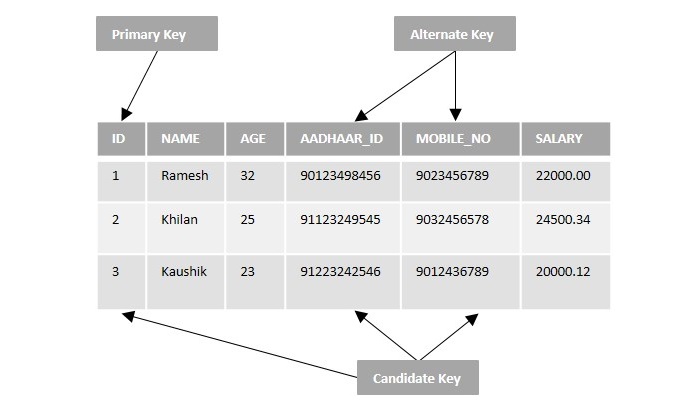
Note − We cannot delete the indexes created by PRIMARY KEY or UNIQUE constraints. In order to delete them, you need to drop the constraints entirely using ALTER TABLE statement.
Syntax
Following is the syntax of the DROP INDEX command in SQL −
DROP INDEX index_name ON table_name;
Here,
- index_name is the name of the index that you want to drop.
- table_name is the name of the table that the index is associated with.
Example
In this example, we will learn how to drop an index on a table named CUSTOMERS, which can be created using the following query −
CREATE TABLE CUSTOMERS( ID INT NOT NULL, NAME VARCHAR(15) NOT NULL, AGE INT NOT NULL, ADDRESS VARCHAR(25), SALARY DECIMAL(10, 4), PRIMARY KEY(ID)); );
Now, insert some values into the above created table using the following query −
INSERT INTO CUSTOMERS VALUES (1, ''Ramesh'', ''32'', ''Ahmedabad'', 2000), (2, ''Khilan'', ''25'', ''Delhi'', 1500), (3, ''Kaushik'', ''23'', ''Kota'', 2000), (4, ''Chaitali'', ''25'', ''Mumbai'', 6500), (5, ''Hardik'',''27'', ''Bhopal'', 8500), (6, ''Komal'', ''22'', ''Hyderabad'', 9000), (7, ''Muffy'', ''24'', ''Indore'', 5500);
Once the table is created, create an index on the column NAME in the CUSTOMERS table using the following query −
CREATE INDEX INDEX_NAME on CUSTOMERS(NAME);
Now, verify if the index is created on the CUSTOMERS table using the following SHOW INDEX query −
SHOW INDEX FROM CUSTOMERS;
On executing the above query, the index list is displayed as follows −
Table Non_unique Key_name Seq_in_index Column_name customers 0 PRIMARY 1 ID customers 1 index_name 1 NAME Then, drop the same index INDEX_NAME in the CUSTOMERS table using the following DROP INDEX statement −
DROP INDEX INDEX_NAME ON CUSTOMERS;
Output
If we compile and run the above query, the result is produced as follows −
Query OK, 0 rows affected (0.02 sec) Records: 0 Duplicates: 0 Warnings: 0
Verification
Verify if the index for the column NAME is dropped using the following query −
SHOW INDEX FROM CUSTOMERS;
In the following list of indexes, you can observe that name of the column Name is missing.
Table Non_unique Key_name Seq_in_index Column_name customers 0 PRIMARY 1 ID DROP INDEX with IF EXISTS
The DROP INDEX IF EXISTS statement in SQL is used to drop an index only if it exists in the table. This statement is specifically useful when you want to drop an index, but you are not sure if the index exists. This clause is not supported by MySQL.
The IF EXISTS clause ensures that the statement only removes the index if it exists. If the index does not exist, it simply terminates the execution.
Syntax
Following is the syntax of the DROP INDEX IF EXISTS in SQL −
DROP INDEX IF EXISTS index_name ON table_name;
Here,
- index_name is the name of the index that you want to drop.
- table_name is the name of the table that the index is associated with.
Example
In this example, let us try to drop an index in the SQL Server database.
Let us consider the previously created table CUSTOMERS and let us create an index for the NAME column in the table using the following query −
CREATE INDEX INDEX_NAME on CUSTOMERS(NAME);
Then, let us drop it using the following query −
DROP INDEX IF EXISTS INDEX_NAME ON CUSTOMERS;
Output
When we execute the above query, the output is obtained as follows −
Commands completed successfully.
Verification
Let”s verify whether the index for the NAME is dropped or not using the following query −
EXEC sys.sp_helpindex @objname = N''CUSTOMERS
As you observe, the column NAME is deleted from the list of indexes.
index_name index_description index_keys PK__CUSTOMER__3214EC27CB063BB7 clustered, unique, primary key locatedPRIMARY on PRIMARY ID Example
Now, let us delete an index that doesn”t exist in the CUSTOMERS table using the following query −
DROP INDEX IF EXISTS INDEX_NAME ON CUSTOMERS;
Output
Since no indexes with the specified name exist in the database, so the above query simply terminates the execution without giving any error.
Commands completed successfully.
Removing indexes created by PRIMARY KEY or UNIQUE
The DROP INDEX statement does not drop indexes created by PRIMARY KEY or UNIQUE constraints. To drop indexes associated with them, we need to drop these constraints entirely. And it is done using the ALTER TABLE… DROP CONSTRAINT statement.
Syntax
Following is the syntax of the ALTER TABLE… DROP CONSTRAINT statement in SQL −
ALTER TABLE table_name DROP CONSTRAINT constraint_name;
Here,
- table_name is the name of the table that contains the PRIMARY KEY constraint.
- constraint_name is the name of the PRIMARY KEY constraint that you want to drop.
Example
Assume the previously created table (CUSTOMERS) and let us first list all the indexes that are created on the table using the following query −
EXEC sys.sp_helpindex @objname = N''CUSTOMERS
The list is displayed as follows −
index_name index_description index_keys PK__CUSTOMER__3214EC27CB063BB7 nonclustered located on PRIMARYID ID Here, the PK__CUSTOMER__3214EC27CB063BB7 is the name of the PRIMARY KEY constraint that was created on the ID column of the CUSTOMERS table.
Now, let us drop the index created by the PRIMARY KEY constraint.
ALTER TABLE customers DROP CONSTRAINT PK__CUSTOMER__3214EC27CB063BB7;
Output
When we execute the above query, the output is obtained as follows −
Commands completed successfully.
Verification
Verify whether it is dropped or not by listing the existing indexes using the following query −
EXEC sys.sp_helpindex @objname = N''CUSTOMERS
The following error is displayed because the list of indexes is empty.
The object ''CUSTOMERS'' does not have any indexes, or you do not have permissions.
Khóa học lập trình tại Toidayhoc vừa học vừa làm dự án vừa nhận lương: Khóa học lập trình nhận lương tại trung tâm Toidayhoc
Khóa học miễn phí SQL – Create Index nhận dự án làm có lương
SQL – Create Index
An index is an effective way to quickly retrieve data from an SQL database. It is a database object that references the data stored in a table, which significantly improves query and application performance of a database.
The process of indexing in SQL is similar to that of an index in a book: it is a database object in the form of a table, contains details of data location, and holds a separate storage space.
Even though indexes help accelerate search queries, users are not able to directly see these indexes in action.
What is SQL Index?
An SQL index is a special lookup table that helps in efficiently searching or querying database tables to retrieve required data. For example, when we try to retrieve data from multiple tables using joins, indexes improve the query performance.
Indexes are used to optimize the query performance of any Relational Database Management System (RDBMS) as data volumes grow. Hence, they are preferred to be used on frequently queried large database tables.
Creating an SQL Index
An index can be created on one or more columns of a table in an SQL database using the CREATE INDEX statement.
Syntax
Following is the syntax of CREATE INDEX statement in SQL −
CREATE INDEX index_name ON table_name (column_name1, column_name2,... column_nameN);
Here,
- index_name This specifies the name of the index that you want to create.
- table_name This specifies the name of the table on which you want to create the index.
- (column_name1, column_name2…column_nameN) are the names of one or more columns on which the index is being created.
Example
To create an index on a database table, we first need to create a table. So, in this example, we are creating a table named CUSTOMERS using the following query −
CREATE TABLE CUSTOMERS( ID INT NOT NULL, NAME VARCHAR(15) NOT NULL, AGE INT NOT NULL, ADDRESS VARCHAR(25), SALARY DECIMAL(10, 4), PRIMARY KEY(ID)); );
Then, insert some values into the CUSTOMERS table using the following query −
INSERT INTO CUSTOMERS VALUES (1, ''Ramesh'', ''32'', ''Ahmedabad'', 2000), (2, ''Khilan'', ''25'', ''Delhi'', 1500), (3, ''Kaushik'', ''23'', ''Kota'', 2000), (4, ''Chaitali'', ''25'', ''Mumbai'', 6500), (5, ''Hardik'',''27'', ''Bhopal'', 8500), (6, ''Komal'', ''22'', ''Hyderabad'', 9000), (7, ''Muffy'', ''24'', ''Indore'', 5500);
Once the table is created, create an index for the column named NAME in the CUSTOMERS table using the following query −
CREATE INDEX index_name ON CUSTOMERS(NAME);
Output
When we execute the above query, the output is obtained as follows −
Query OK, 0 rows affected (0.06 sec) Records: 0 Duplicates: 0 Warnings: 0
Verification
The following SHOW INDEX query is used to display all the indexes created on an existing table.
SHOW INDEX FROM CUSTOMERS;
In the list obtained, you can find the column name NAME, along with the ID in the list of indexes.
| Table | Non_unique | Key_name | Seq_in_index | Column_name |
|---|---|---|---|---|
| customers | 0 | PRIMARY | 1 | ID |
| customers | 1 | index_name | 1 | NAME |
Creating an Index on Multiple Fields
We can also create an index on multiple fields (or columns) of a table using the CREATE INDEX statement. To do so, you just need to pass the name of the columns (you need to create the index on).
Example
Instead of creating a new table, let us consider the previously created CUSTOMERS table. Here, we are creating an index on the columns NAME and AGE using the following query −
CREATE INDEX mult_index_data on CUSTOMERS(NAME, AGE);
Output
When we execute the above query, the output is obtained as follows −
Query OK, 0 rows affected (0.04 sec) Records: 0 Duplicates: 0 Warnings: 0
Verification
Now, let us list all the indexes that are created on the CUSTOMERS table using the following SHOW INDEX query −
SHOW INDEX FROM CUSTOMERS;
As you observe, you can find the column names NAME, and AGE along with ID (PRIMARY KEY), in the list of indexes.
| Table | Non_unique | Key_name | Seq_in_index | Column_name |
|---|---|---|---|---|
| customers | 0 | PRIMARY | 1 | ID |
| customers | 1 | index_name | 1 | NAME |
| customers | 1 | mult_index_data | 1 | NAME |
| customers | 1 | mult_index_data | 2 | AGE |
Khóa học lập trình tại Toidayhoc vừa học vừa làm dự án vừa nhận lương: Khóa học lập trình nhận lương tại trung tâm Toidayhoc