Your cart is currently empty!
Author: alien
-
Khóa học miễn phí Map Reduce & Aggregations nhận dự án làm có lương
Hazelcast – Map Reduce & Aggregations
MapReduce is a computation model which is useful for data processing when you have lots of data and you need multiple machines, i.e., a distributed environment to calculate data. It involves ”map”ing of data into key-value pairs and then ”reducing”, i.e., grouping these keys and performing operation on the value.
Given the fact that Hazelcast is designed keeping a distributed environment in mind, implementing Map-Reduce Frameworks comes naturally to it.
Let’s see how to do it with an example.
For example, let”s suppose we have data about a car (brand & car number) and the owner of that car.
Honda-9235, John Hyundai-235, Alice Honda-935, Bob Mercedes-235, Janice Honda-925, Catnis Hyundai-1925, Jane
And now, we have to figure out the number of cars for each brand, i.e., Hyundai, Honda, etc.
Example
Let”s try to find that out using MapReduce −
package com.example.demo; import java.lang.reflect.Array; import java.util.ArrayList; import java.util.Map; import java.util.concurrent.ExecutionException; import java.util.concurrent.atomic.AtomicInteger; import com.hazelcast.core.Hazelcast; import com.hazelcast.core.HazelcastInstance; import com.hazelcast.core.ICompletableFuture; import com.hazelcast.core.IMap; import com.hazelcast.mapreduce.Context; import com.hazelcast.mapreduce.Job; import com.hazelcast.mapreduce.JobTracker; import com.hazelcast.mapreduce.KeyValueSource; import com.hazelcast.mapreduce.Mapper; import com.hazelcast.mapreduce.Reducer; import com.hazelcast.mapreduce.ReducerFactory; public class MapReduce { public static void main(String[] args) throws ExecutionException, InterruptedException { try { // create two Hazelcast instances HazelcastInstance hzMember = Hazelcast.newHazelcastInstance(); Hazelcast.newHazelcastInstance(); IMap<String, String> vehicleOwnerMap=hzMember.getMap("vehicleOwnerMap"); vehicleOwnerMap.put("Honda-9235", "John"); vehicleOwnerMap.putc"Hyundai-235", "Alice"); vehicleOwnerMap.put("Honda-935", "Bob"); vehicleOwnerMap.put("Mercedes-235", "Janice"); vehicleOwnerMap.put("Honda-925", "Catnis"); vehicleOwnerMap.put("Hyundai-1925", "Jane"); KeyValueSource<String, String> kvs=KeyValueSource.fromMap(vehicleOwnerMap); JobTracker tracker = hzMember.getJobTracker("vehicleBrandJob"); Job<String, String> job = tracker.newJob(kvs); ICompletableFuture<Map<String, Integer>> myMapReduceFuture = job.mapper(new BrandMapper()) .reducer(new BrandReducerFactory()).submit(); Map<String, Integer&g; result = myMapReduceFuture.get(); System.out.println("Final output: " + result); } finally { Hazelcast.shutdownAll(); } } private static class BrandMapper implements Mapper<String, String, String, Integer> { @Override public void map(String key, String value, Context<String, Integer> context) { context.emit(key.split("-", 0)[0], 1); } } private static class BrandReducerFactory implements ReducerFactory<String, Integer, Integer> { @Override public Reducer<Integer, Integer> newReducer(String key) { return new BrandReducer(); } } private static class BrandReducer extends Reducer<Integer, Integer> { private AtomicInteger count = new AtomicInteger(0); @Override public void reduce(Integer value) { count.addAndGet(value); } @Override public Integer finalizeReduce() { return count.get(); } } }Let’s try to understand this code −
- We create Hazelcast members. In the example, we have a single member, but there can well be multiple members.
-
We create a map using dummy data and create a Key-Value store out of it.
-
We create a Map-Reduce job and ask it to use the Key-Value store as the data.
-
We then submit the job to cluster and wait for completion.
-
The mapper creates a key, i.e., extracts brand information from the original key and sets the value to 1 and then emits that information as K-V to the reducer.
-
The reducer simply sums the value, grouping the data, based on key, i.e., brand name.
Output
The output of the code −
Final output: {Mercedes=1, Hyundai=2, Honda=3}
Khóa học lập trình tại Toidayhoc vừa học vừa làm dự án vừa nhận lương: Khóa học lập trình nhận lương tại trung tâm Toidayhoc
Khóa học miễn phí Hazelcast – Monitoring nhận dự án làm có lương
Hazelcast – Monitoring
Hazelcast provides multiple ways to monitor the cluster. We will look into how to monitor via REST API and via JMX. Let”s first look into REST API.
Monitoring Hazelcast via REST API
To monitor health of the cluster or member state via REST API, one has to enable REST API based communication to the members. This can be done by configuration and also programmatically.
Let us enable REST based monitoring via XML configuration in hazelcast-monitoring.xml −
<hazelcast
xsi:schemaLocation="http://www.hazelcast.com/schema/config
http://www.hazelcast.com/schema/config/hazelcast-config-3.12.12.xsd"
xmlns="http://www.hazelcast.com/schema/config"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<instance-name>XML_Hazelcast_Instance</instance-name>
<network>
<rest-api enabled="true">
<endpoint-group name="CLUSTER_READ" enabled="true" />
<endpoint-group name="HEALTH_CHECK" enabled="true" />
</rest-api>
</network>
</hazelcast>
Let us create a Hazelcast instance which runs indefinitely in Server.java file −
public class Server {
public static void main(String... args){
//initialize hazelcast server/instance
HazelcastInstance hazelcast = Hazelcast.newHazelcastInstance();
// do not shutdown, let the server run
//hazelcast.shutdown();
}
}
And now let us execute start the cluster −
java ''-Dhazelcast.config=hazelcast-monitoring.xml'' -cp .targetdemo-0.0.1- SNAPSHOT.jar com.example.demo.Server
Once started, the health of the cluster can be found out by calling the API like −
http://localhost:5701/hazelcast/health
The output of the above API call −
Hazelcast::NodeState=ACTIVE Hazelcast::ClusterState=ACTIVE Hazelcast::ClusterSafe=TRUE Hazelcast::MigrationQueueSize=0 Hazelcast::ClusterSize=1
This displays that there is 1 member in our cluster and it is Active.
More detailed information about the nodes, for example, IP, port, name can be found using −
http://localhost:5701/hazelcast/rest/cluster
The output of the above API −
Members {size:1, ver:1} [
Member [localhost]:5701 - e6afefcb-6b7c-48b3-9ccb-63b4f147d79d this
]
ConnectionCount: 1
AllConnectionCount: 2
JMX monitoring
Hazelcast also supports JMX monitoring of the data structures embedded inside it, for example, IMap, Iqueue, and so on.
To enable JMX monitoring, we first need to enable JVM based JMX agents. This can be done by passing “-Dcom.sun.management.jmxremote” to the JVM. For using different ports or use authentication, we can use -Dcom.sun.management.jmxremote.port, – Dcom.sun.management.jmxremote.authenticate, respectively.
Apart from this, we have to enable JMX for Hazelcast MBeans. Let us enable JMX based monitoring via XML configuration in hazelcast-monitoring.xml −
<hazelcast
xsi:schemaLocation="http://www.hazelcast.com/schema/config
http://www.hazelcast.com/schema/config/hazelcast-config-3.12.12.xsd"
xmlns="http://www.hazelcast.com/schema/config"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<instance-name>XML_Hazelcast_Instance</instance-name>
<properties>
<property name="hazelcast.jmx">true</property>
</properties>
</hazelcast>
Let us create a Hazelcast instance which runs indefinitely in Server.java file and add a map −
class Server {
public static void main(String... args){
//initialize hazelcast server/instance
HazelcastInstance hazelcast = Hazelcast.newHazelcastInstance();
//create a simple map
Map<String, String> vehicleOwners = hazelcast.getMap("vehicleOwnerMap");
// add key-value to map
vehicleOwners.put("John", "Honda-9235");
// do not shutdown, let the server run
//hazelcast.shutdown();
}
}
Now we can execute the following command to enable JMX −
java ''-Dcom.sun.management.jmxremote'' ''-Dhazelcast.config=othershazelcastmonitoring. xml'' -cp .targetdemo-0.0.1-SNAPSHOT.jar com.example.demo.Server
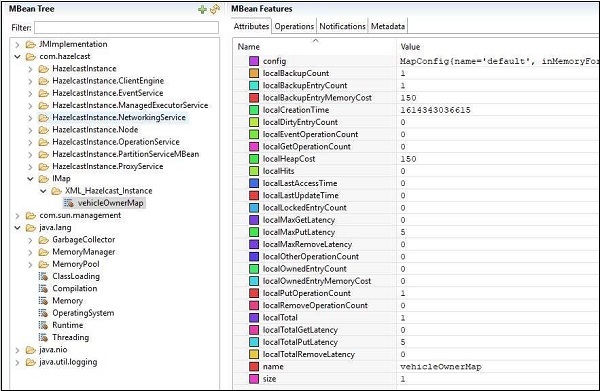
The JMX ports can now be connected by JMX clients like jConsole, VisualVM, etc.
Here is a snapshot of what we will get if we connect using jConsole and see the attributes for VehicleMap. As we can see, the name of the map as vehicleOwnerMap and the size of map being 1.
Khóa học lập trình tại Toidayhoc vừa học vừa làm dự án vừa nhận lương: Khóa học lập trình nhận lương tại trung tâm Toidayhoc
